ColiVara: a state of the art retrieval API with a delightful developer experience.
ColiVara stores, searches, and retrieves documents based on their visual embedding.
We are launching ColiVara today!
ColiVara is a state of the art retrieval API that stores, searches, and retrieves documents based on their visual embedding. End to end it uses vision models instead of chunking and text-processing for documents.
In simple terms, we ask the AI models to "see" and reason, rather "read", and reason. From the user's perspective, it functions like retrieval augmented generation (RAG) but uses vision models instead of chunking and text-processing for documents.
You can read more about the project on Github or browse the documentations. You can also try it for free at colivara.com.
Why?
RAG (Retrieval Augmented Generation) is a powerful technique that allows us to enhance large language models (LLMs) output with private documents and proprietary knowledge that is not available elsewhere. For example, a company's internal documents or a researcher's notes.
However, it is limited by the quality of the text extraction pipeline. With limited ability to extract visual cues and other non-textual information, RAG can be suboptimal for documents that are visually rich. ColiVara uses vision models to generate embeddings for documents, allowing you to retrieve documents based on their visual content.
In addition to RAG, ColiVara works as a visual data extraction pipeline. Most systems today don't have APIs and for LLMs to interact with them, they have to process everything visually. ColiVara allows you to treat anything as an image - and get whatever data from there, the same way a human would. What you see, is what you get.
Tech
ColiVara is a web-first implementation of the ColPali: Efficient Document Retrieval with Vision Language Models paper, featuring several optimizations. First, we re-implemented the scoring from the paper using Postgres and Pgvector, wrapped in Django ORM. This allows any developer to use the API and contribute. There's no need for PyTorch, CUDA, or code that only works in notebooks but not on servers.
For the embeddings, we dockerized and optimized the pipeline for serverless workloads.
Finally, we built the entire pipeline as an API with a great developer experience to support production workloads.
Evals
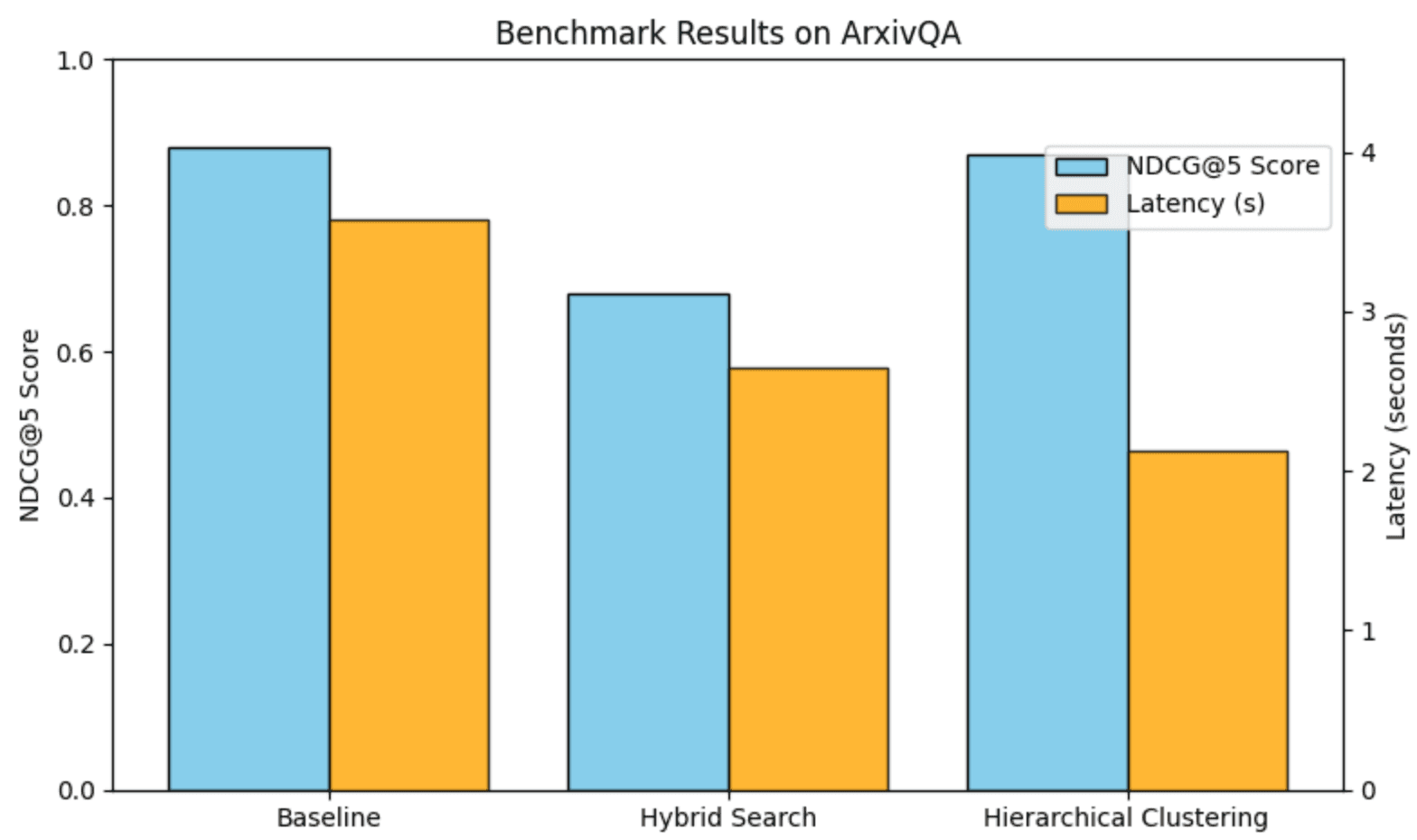
We will write a dedicated article to our evaluation process, including reproducibility and continuous improvements. The latest benchmark score we hit is an ArxivQ score of 86.6 - matching state of the art results in the Vidore leaderboard and a score higher than the original ColPali paper which scored at 79.1.

Usage
We use vision models a ton today in production and ColiVara is informed by our use-cases. I will highlight a couple here:
We automate the data entry and processing of about 10,000 prescriptions/week today, working with Lilly Direct and Gifthealth pharmacy. These tasks, often need to be read and reason on what is in the screen. Sometimes- we need to save and search through all of this data. We use ColiVara to power the image workflows and search.
For traditional RAG, we would like to highlight OnLabel.ai - something we alsoworked on. Often, we get all kind of documents. From manufacturers drug discount coupons, to large unorganized tables, to charts inside PowerPoint, and many clinical trials where the main takeaways are summarized in charts and tables.
We built ColiVara to solve for difficult tasks, where accuracy and recall must be precise and happen over visually rich documents.
Quickstart
Get a free API Key from the ColiVara Website.
Install the Python SDK and use it to interact with the API.
pip install colivara-pyIndex a document. Colivara accepts a file url, or base64 encoded file, or a file path. We support over 100 file formats including PDF, DOCX, PPTX, and more. We will also automatically take a screenshot of URLs (webpages) and index them.
from colivara_py import ColiVara client = ColiVara( # this is the default and can be omitted api_key=os.environ.get("COLIVARA_API_KEY"), # this is the default and can be omitted base_url="https://api.colivara.com" ) # Upload a document to the default_collection document = client.upsert_document( name="sample_document", url="https://example.com/sample.pdf", # optional - add metadata metadata={"author": "John Doe"}, # optional - specify a collection collection_name="user_1_collection", # optional - wait for the document to index wait=True )Search for a document. You can filter by collection name, collection metadata, and document metadata. You can also specify the number of results you want.
# Simple search results = client.search("what is 1+1?") # search with a specific collection results = client.search("what is 1+1?", collection_name="user_1_collection") # Search with a filter on document metadata results = client.search( "what is 1+1?", query_filter={ "on": "document", "key": "author", "value": "John Doe", "lookup": "key_lookup", # or contains }, ) # Search with a filter on collection metadata results = client.search( "what is 1+1?", query_filter={ "on": "collection", "key": ["tag1", "tag2"], "lookup": "has_any_keys", }, ) # top 3 pages with the most relevant information print(results)
Key Features
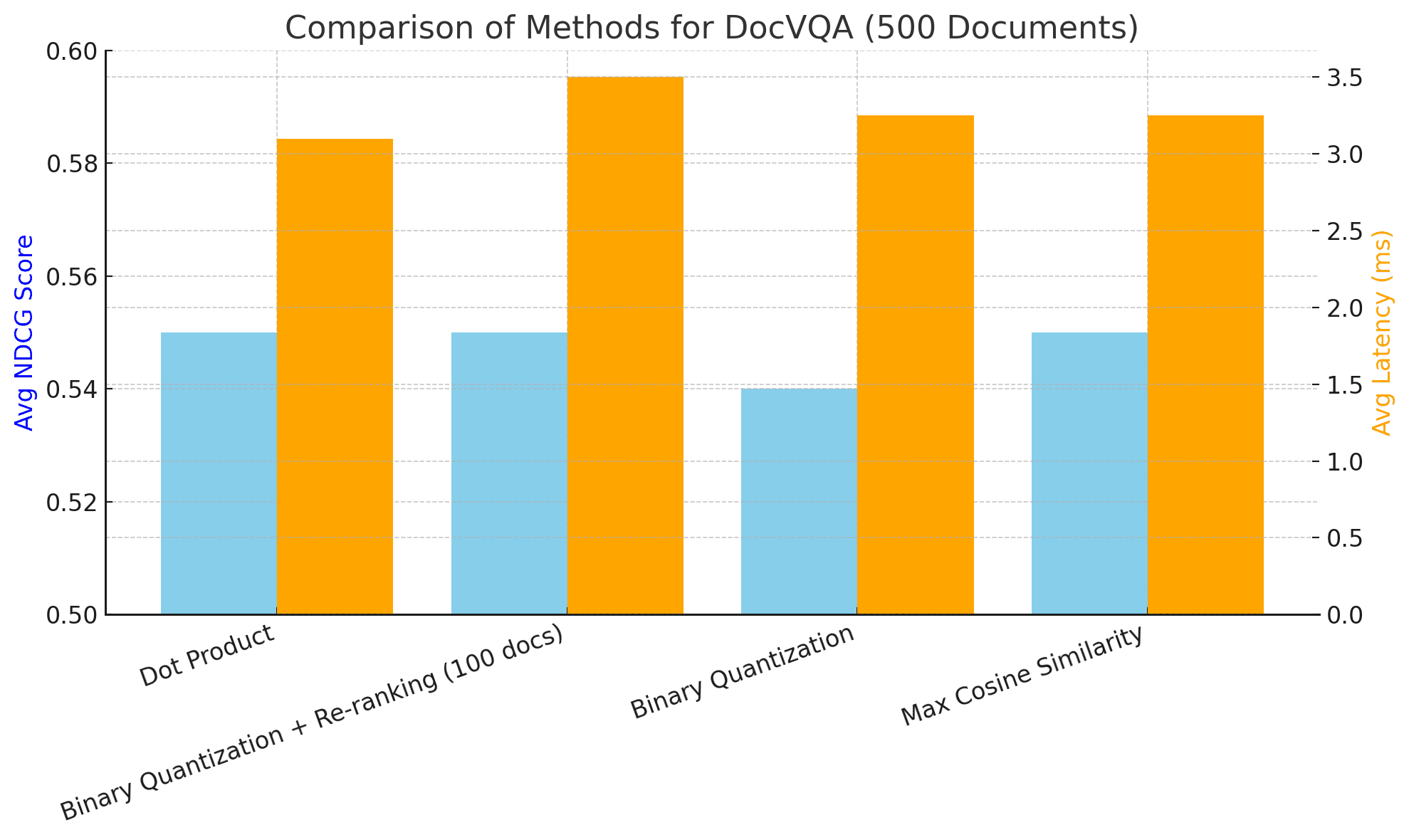
State of the Art retrieval: The API is based on the ColPali paper and uses the ColQwen2 model for embeddings. It outperforms existing retrieval systems on both quality and latency.
User Management: Multi-user setup with each user having their own collections and documents.
Wide Format Support: Supports over 100 file formats including PDF, DOCX, PPTX, and more.
Webpage Support: Automatically takes a screenshot of webpages and indexes them even if it is not a file.
Collections: A user can have multiple collections. For example, a user can have a collection for research papers and another for books. Allowing for efficient retrieval and organization of documents.
Documents: Each collection can have multiple documents with unlimited and user-defined metadata.
Filtering: Filtering for collections and documents on arbitrary metadata fields. For example, you can filter documents by author or year. Or filter collections by type.
Convention over Configuration: The API is designed to be easy to use with opinionated and optimized defaults.
Modern PgVector Features: We use HalfVecs for faster search and reduced storage requirements.
REST API: Easy to use REST API with Swagger documentation.
Comprehensive: Full CRUD operations for documents, collections, and users.
Dockerized: Easy to setup and run with Docker and Docker Compose.
Self-hosting
ColiVara is available for self-hosting and we provide commercial support. It is licensed under Functional Source License, Version 1.1, Apache 2.0 Future License.
For questions, please contact us at founders@tjmlabs.com. We are happy to work with you to provide an agreement that meets your needs.